
はじめに
今回はPythonでスクレイピングを行ってみたいと思います。
皆さんWebサイトのデータを収集したいときはどうしますか?
などなど、普段ブラウザでアクセスするページから、直接データを取得したい時ってありますよね!
それらのデータを、ブラウザを開いていちいちコピペで収集・・というのは現実的ではありません。
そこでPythonを使い、Webサイトのデータを自動的に取得してみましょう!
他にも私のブログで、Pythonについて解説している記事がありますのでご覧ください。


スクレイピングとは
ウェブスクレイピング(Web scraping)とは、ウェブサイトから情報を収集する技術のことです。
連携する金融機関が、以降に説明したAPIに対応していない場合は、スクレイピングでデータを取得していると思います。
金融機関と連携するには、事前にID/パスワードを登録しますよね?
要はユーザーの代わりに、金融機関のサイトにログインして、必要な情報を取得しているのです。
APIについて
ちなみに、サイトにAPIが用意されている場合はスクレイピングの必要はありません。
例えば、APIでお天気情報が取得できるサイトがあります。
APIはサイトが公式に用意している手段ですので、仕様が変わる可能性も低く合法的に取得できますので、この仕組みを使うのが一番良いです。
スクレイピングは、APIなどでデータが取得できない場合に、ウェブサイトのページの内容を解析してデータを取得します。
スクレイピングの注意点
スクレイピングは、ウェブページの内容(HTML)を解析する性質上、対象のウェブページの構成が変わった場合に、スクレイピングのプログラムを修正する必要があります。
また違法かどうかも注意が必要です。
ウェブサイトにスクレイピングする際は各自でご確認ください。
スクレイピングが直接の原因だったわけではありませんが、参考までに過去にも事件があります。

前置きが長くなりましたが、実際にプログラムを作ってみたいと思います。
ソースコードについて
今回使用するソースコードはGitHubにて公開しています。
環境
以下の環境があれば、WindowsでもMacでも構いません。
それぞれのライブラリはpipでインストールできます。
pip3 install beautifulsoup4
pip3 install html5libDockerイメージを使う
Dockerコンテナを使用して解説していきます。
Dockerのインストール方法は、以下の記事をご覧ください。


スクレピングに必要な環境が揃ったイメージは、以下に公開しております。

上記のイメージの作り方につきましては、下記の記事をご覧ください。

Dockerコマンドで、イメージをダウンロードします。
docker pull chigusaweb/python-scraping以下のコマンドで、Dockerコンテナを作成しました。
docker run -it -v D:\Docker\share:/root/share --name py-sc chigusaweb/python-scraping:latest /bin/bashdocker run -it -v /Users/xxx/Documents/Docker/share:/root/share --name py-sc chigusaweb/python-scraping:latest /bin/bashコンテナの中に入った後、カレントディレクトリを移動します。
このディレクトリがホスト(WindowsまたはMac)と共有されています。
cd /root/share/またVS Codeを使えば、コンテナ環境での開発が簡単にできますので、こちらもオススメです。
参考にしてください。

HTMLファイルダウンロード
それではスクレイピングを始めましょう。
まずは、対象ページのHTMLファイルをダウンロードします。
その都度、サイトにアクセスすると迷惑がかかりますし、効率がよくありません。
そのため、対象サイトのページのHTMLファイルを一度ダウンロードし、以降はそのHTMLファイルを読み込んで解析処理を作っていきます。
ダウンロードしたHTMLファイルを何度も解析する分には、サイトには迷惑かけませんからね!
HTMLファイルをダウンロードするPythonファイルを作成します。
Dockerコンテナとフォルダを共有していますので、共有フォルダの中にPythonファイルを作成します。
Windows例:
D:\Docker\share\donwload.py
Mac例:
/Users/xxx/Documents/Docker/share/donwload.py
ソースコードは以下です。UTF-8で保存してください。
import os
from urllib.request import *
print("ダウンロード開始")
# HTMLファイル 保存先のディレクトリ
save_dir = os.path.dirname(os.path.abspath(__file__)) + "/html/"
# 存在しなければディレクトリ作成
if not os.path.exists(save_dir):
os.mkdir(save_dir)
# htmlをダウンロードするURL
# ここでは千草ウェブのトップページ
download_url = "https://chigusa-web.com/"
# 保存先
save_file = save_dir + "/chigusa.html"
# ダウンロード
urlretrieve(download_url, save_file)
print("ダウンロード完了")Pythonファイルを保存しましたら、実行します。
Dockerのコンテナへ入っている状態で、ファイルがあるか確認します。
root@896a267e9c03:~/share# cd /root/share/
root@896a267e9c03:~/share# ls
download.py作成したPythonを実行します。
root@896a267e9c03:~/share# python download.py
ダウンロード開始
ダウンロード完了Pythonファイルと同じ階層に、htmlフォルダが作成され、中にhtmlファイルが作成されます。
Windows例:
D:\Docker\share\html\chigusa.html
Mac例:
/Users/xxx/Documents/Docker/share/html/chigusa.html
上記のHTMLファイルをテキストエディタで確認してみてください。このサイトのトップページのHTMLになります。
引き続きこのHTMLファイルを解析していきます。
HTMLの解析
次に、先程ダウンロードしたHTMLファイルを読み込み、解析を行っていきます。
本サイトのトップページを例としています。
文字列をピンポイントで取得
以下のタイトルの文字列を取得してみます。
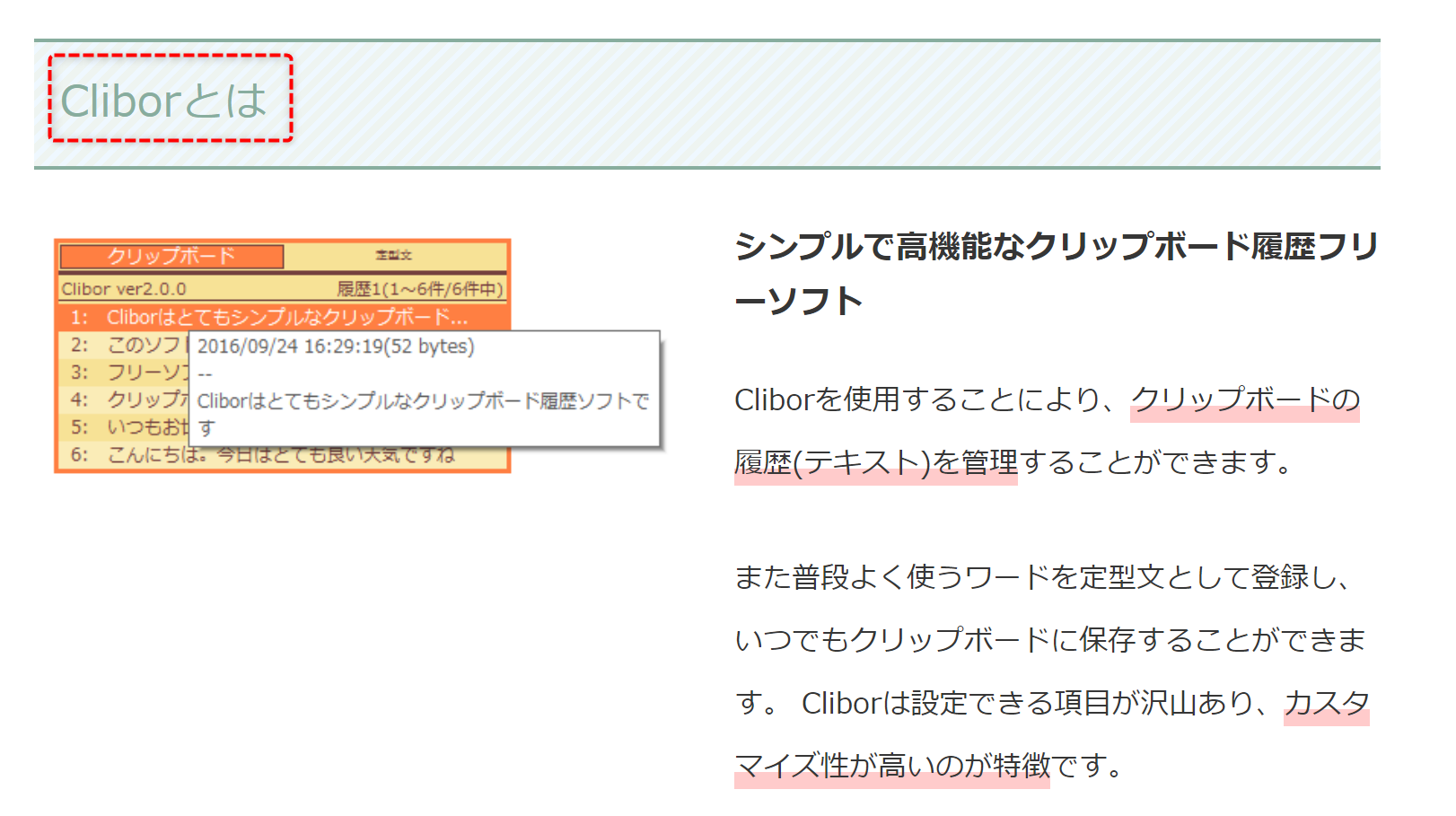
まずは該当の文字列の場所を特定します。
実際はHTMLを解析しますので、特定方法はCSSのセレクターを取得します。
ブラウザのFirefoxを使用します。
(Chromeや他のブラウザですと以降の手順で上手くできません)
Firefoxで該当のURLを開きます。(今回は本サイトのトップページ)
F12キーを押し、開発ツールを起動します。
起動後、以下の赤枠の矢印マークをクリックします。
ブラウザの方に戻り、取得したい文字列を選択しクリックします。
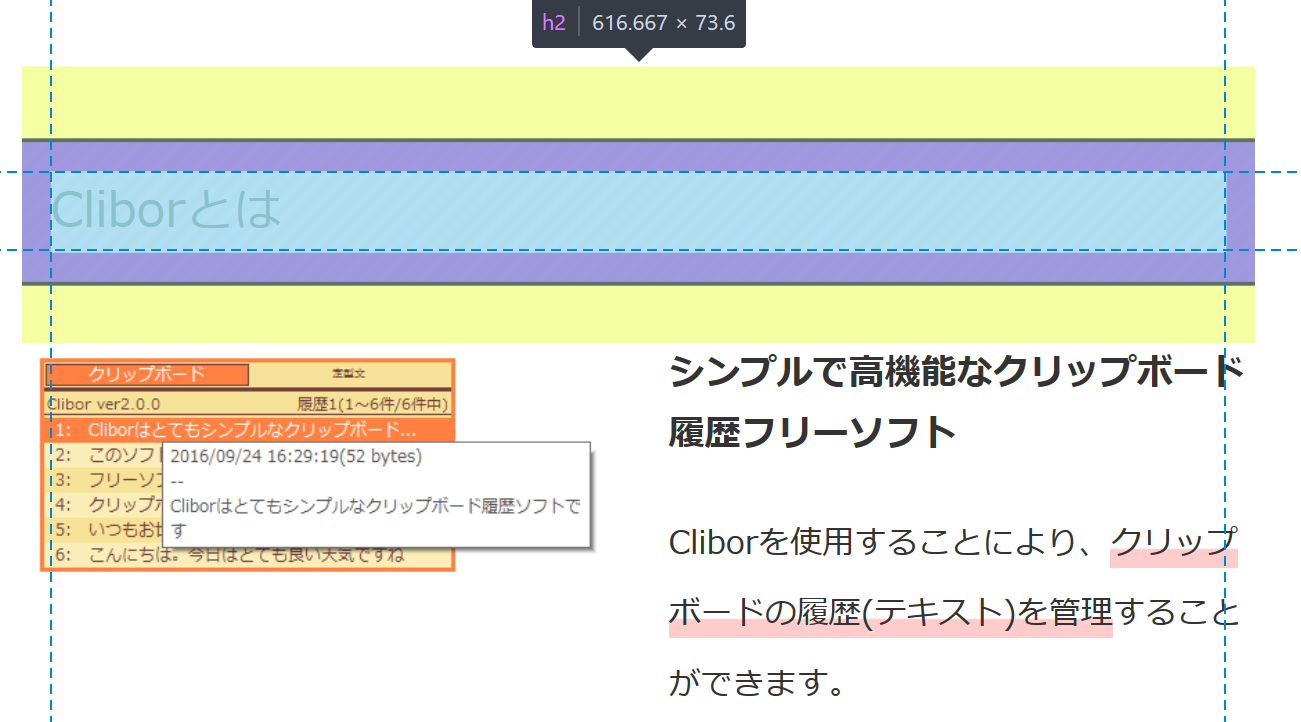
開発ツールに戻り、選択された文字列を右クリックし、コピー→CSSセレクターをクリックします。
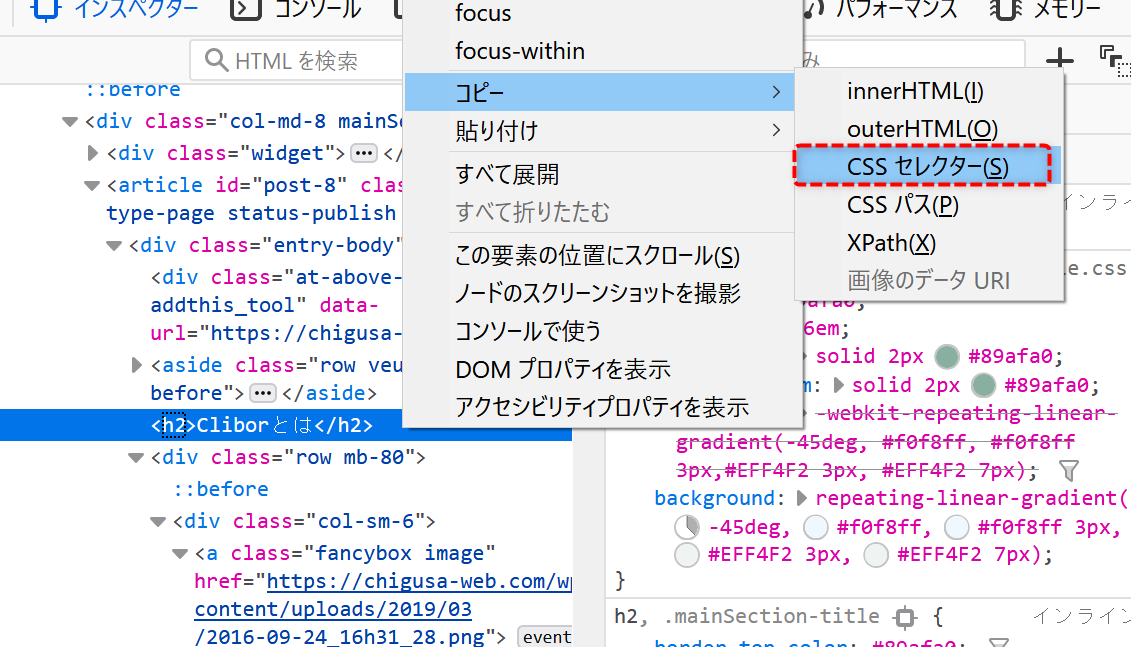
以下のような文字列がクリップボードに格納されました。
今回のページの中で、取得したい文字列の場所を特定するものです。
.entry-body > h2:nth-child(4)
上記の文字列が分かれば、Python側で文字列を取得してみたいと思います。
処理内容としては、先にダウンロードしたHTMLファイルの中身を読み込み、HTMLを解析することによって、ピンポイントで文字列を取得します。
HTMLの解析にはBeautifulSoupを使用し、該当の文字列を取得する際に先に取得したCSSセレクターを指定しています。
import os
from bs4 import BeautifulSoup
print("HTML解析開始")
# HTMLファイル 保存先のディレクトリ
save_dir = os.path.dirname(os.path.abspath(__file__)) + "/html/"
# HTMLファイルパス
html_file = save_dir + "/chigusa.html"
# ファイルの読み込み
with open(html_file, encoding='utf-8') as f:
bsoup = BeautifulSoup(f, "html5lib")
# HTMLから該当の文字を取得(CSSセレクターを指定)
ele = bsoup.select_one(".entry-body > h2:nth-child(4)")
if ele is None:
print("見つかりませんでした")
else:
print("見つかりました:" + ele.string)
print("HTML解析終了")それではPythonを実行してみましょう。
「Cliborとは」という文字列を取得できましたね!
root@896a267e9c03:~/share# python analysis1.py
HTML解析開始
見つかりました:Cliborとは
HTML解析終了繰り返し要素を複数取得
次は、複数の要素を取得してみたいと思います。
例として、このサイトのトップページの、ブログ記事一覧の各タイトルを取得したいと思います。
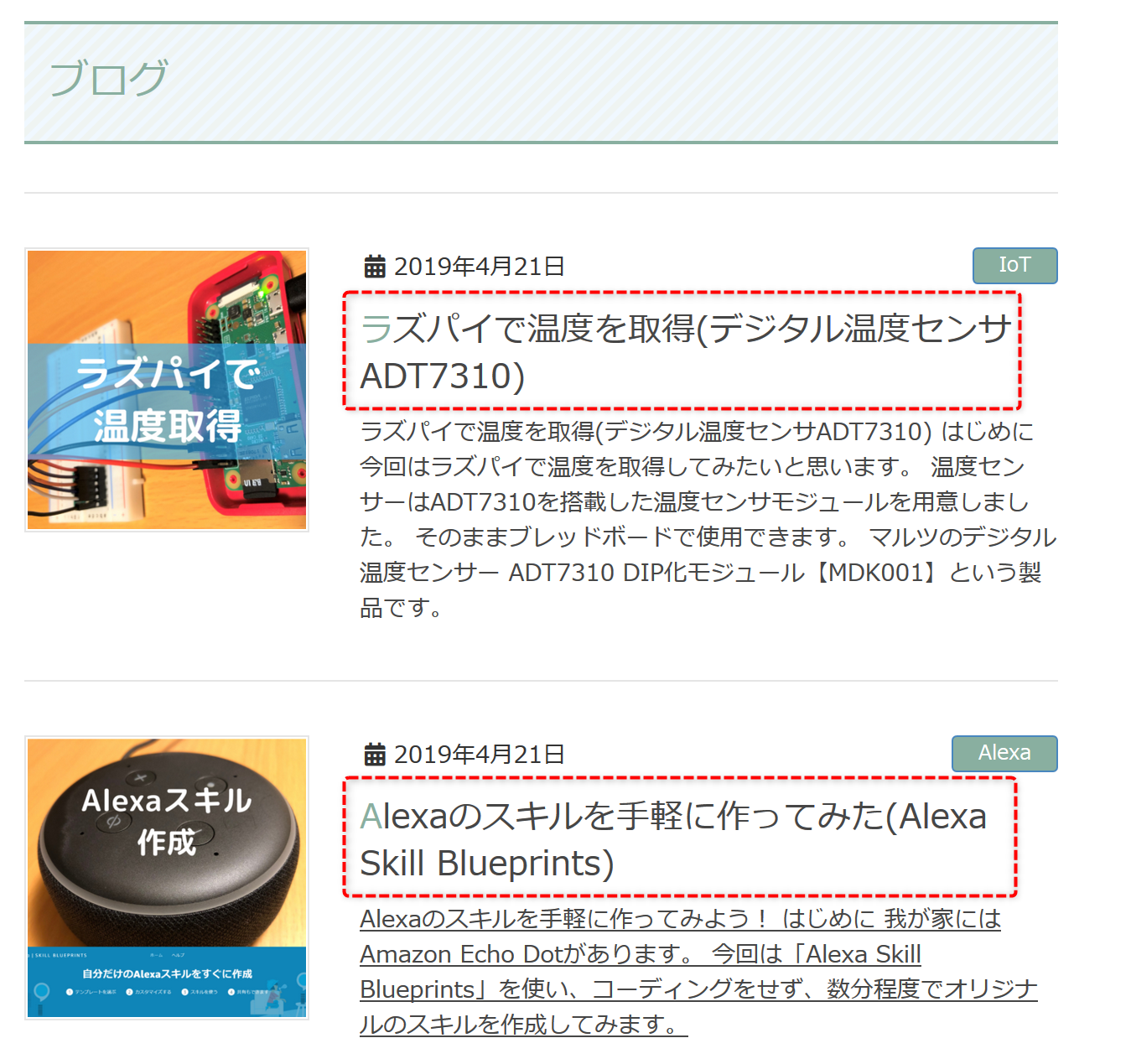
先程同様に、Firefoxの開発ツールでCSSセレクターを探しましょう。
CSSのclassで良さげなものがあればよいのですが、今回は少し難しそうです。
まずはブログの記事一覧のエリアのCSSセレクターを取得します。
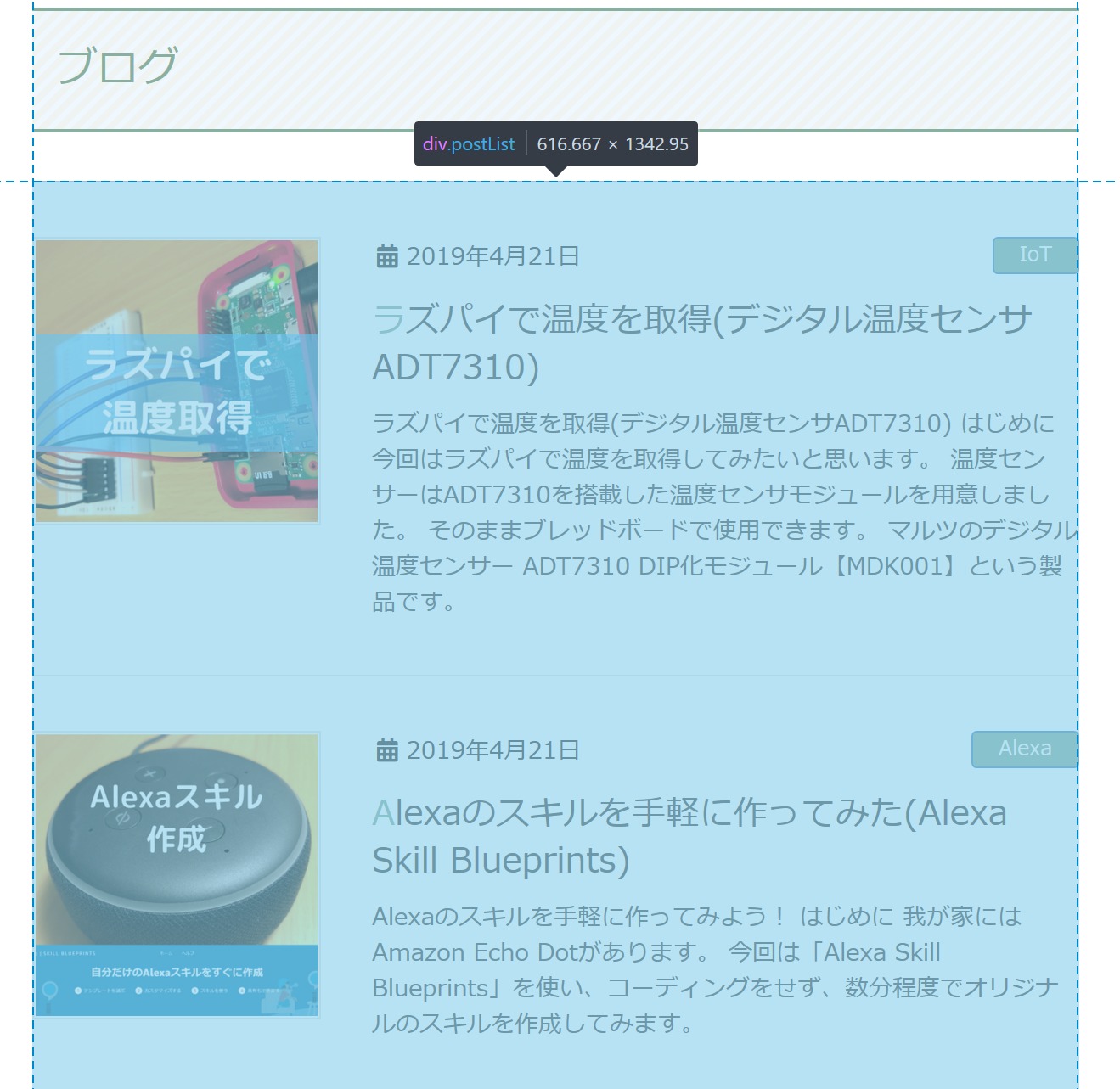
CSSセレクターは以下です。
div.postList:nth-child(4)
HTMLを見てみると、このエリアの中のh1タグを全て取得し、さらにその中のaタグの値を取得すると、タイトルが取れそうです。
プログラムは以下のようにしました。
import os
from bs4 import BeautifulSoup
print("HTML解析開始")
# HTMLファイル 保存先のディレクトリ
save_dir = os.path.dirname(os.path.abspath(__file__)) + "/html/"
# HTMLファイルパス
html_file = save_dir + "/chigusa.html"
# ファイル読み込み
with open(html_file, encoding='utf-8') as f:
bsoup = BeautifulSoup(f, "html5lib")
# HTMLから該当の範囲を取得
ele = bsoup.select_one("div.postList:nth-child(4)")
if ele is None:
print("見つかりませんでした")
else:
# h1タグのリストを取得
allTitles = ele.find_all("h1")
for h1 in allTitles:
# h1の中のaタグの表示文字列を取得
print(h1.select_one("a").string)
print("HTML解析終了")実行してみると以下のようになり、上手く取得ができました!
root@896a267e9c03:~/share# python analysis2.py
HTML解析開始
ラズパイで温度を取得(デジタル温度センサADT7310)
Alexaのスキルを手軽に作ってみた(Alexa Skill Blueprints)
ラズパイとNode-REDを使って簡単にLチカ!
ラズパイにNode-REDをインストール
ラズパイZeroでLチカ!(Python編)
HTML解析終了find_allを使用すると、Tableタグのtrタグを複数取得するのも可能です。
スクレイピング結果をテキストファイルに保存
取得した情報を、テキストファイルに保存しましょう。
先程のタイトル一覧を保存するプログラムを作成しました。
import os
from bs4 import BeautifulSoup
print("HTML解析開始")
# HTMLファイル 保存先のディレクトリ
save_dir = os.path.dirname(os.path.abspath(__file__)) + "/html/"
# HTMLファイルパス
html_file = save_dir + "/chigusa.html"
# 保存先テキストファイル
save_file = os.path.dirname(os.path.abspath(__file__)) + "/save.txt"
if os.path.exists(save_file):
os.remove(save_file)
# ファイルの読み込み・書き込み
with open(save_file, 'a', encoding='utf-8') as fw, open(html_file, encoding='utf-8') as f:
bsoup = BeautifulSoup(f, "html5lib")
# HTMLから該当の範囲を取得
ele = bsoup.select_one("div.postList:nth-child(4)")
if ele is None:
print("見つかりませんでした")
else:
# h1タグのリストを取得
allTitles = ele.find_all("h1")
for h1 in allTitles:
title = h1.select_one("a").string
# h1の中のaタグの表示文字列を取得
print(title)
# テキストファイルに保存
fw.write(title + "\n")
print("HTML解析終了")実行したPythonファイルと同階層にTXTファイルを出力しました。
以下の共有フォルダにTXTファイルが出力されていると思います。
Windows例:
D:\Docker\share\save.txt
Mac例:
/Users/xxx/Documents/Docker/share/save.txt
テキストファイルの中身にタイトルの一覧が保存されます。
ラズパイで温度を取得(デジタル温度センサADT7310)
Alexaのスキルを手軽に作ってみた(Alexa Skill Blueprints)
ラズパイとNode-REDを使って簡単にLチカ!
ラズパイにNode-REDをインストール
ラズパイZeroでLチカ!(Python編)
最後に
今回はPythonを使用して、htmlファイルをダウンロードし、解析を行いました。
意外にやってみると簡単にできますね!
ただし、Webページによっては、Javascriptで動的にページを表示する場合もあるかと思います。
その場合には今回のやり方はではできず、また別なやり方で行うことができます。
そのやり方も別途まとめて行きたいと思います。
他にも私のブログで、Pythonについて解説している記事がありますのでご覧ください。






コメント